
L’internet est une source absolument massive de données. Cependant, l’extraction de ces données n’est pas toujours simple comme on l’aurait souhaité. Le Web Scrapping est une solution pour capturer des données à partir de nombreux sites Web.
De nombreux projets d’analyse de données, de mégadonnées et d’apprentissage automatique nécessitent l’extraction automatique des données alors qu’internet est une source absolument massive de données, l’extraction des données provenant d’un ou plusieurs sites web n’est pas toujours simple comme on l’aurait souhaité. Imaginez que vous devriez extraire une grande quantité de données de sites Web et que vous souhaiteriez le faire le plus rapidement possible, pourtant celles-ci ne sont disponibles dans des fichiers CSV bien organisés pour le téléchargement et l’analyse… En effet, une solution pour capturer des données à partir de nombreux sites Web est le scraping Web.
Le Web Scraping (appelé également extraction de données Web) est officiellement connue sous le nom de processus de stockage et de structuration de données à partir du Web à l’aide d’une automatisation intelligente. Ce processus peut être utilisé pour récupérer potentiellement des centaines, des millions, voire des milliards de points de données de la frontière de l’internet. C’est pourquoi les entreprises telles que Walmart, CNN, Target et Amazon utilisent le web scraping , ce qui leur donne une longueur d’avance par rapport à d’autres entreprises en ce qui a trait aux données.
Dans ce tutoriel, nous allons présenter l’utilisation du Web Scraping avec des requêtes et Beautifulsoup pour récupérer et analyser les données du Web.
Le Web scraping est-il légal?
Certains sites Web autorisent explicitement le web scraping, pourtant d’autres l’interdisent. De nombreux sites Web n’offrent aucune orientation claire dans un sens ou dans l’autre.
Par ailleurs, en ce qui concernen le web scraping, Il est judicieux de suivre tout un ensemble de bonnes pratiques :
- Ne vous engagez pas dans le piratage ou toute autre utilisation commerciale non autorisée des données que vous extrayez. Pour savoir si un site Web autorise ou non le scraping Web, vous pouvez consulter le fichier « robots.txt » du site Web.
- Le web scraping consomme des ressources serveur pour le site Web hôte. Ne spammez pas le site Web avec plusieurs demandes dans un court laps de temps, car cela pourrait les offenser et / ou être classé comme une attaque DDOS.
Si vous ne récupérez qu’une seule page, cela ne posera pas de problème. Mais si notre code récupère 1000 pages toutes les dix minutes, cela pourrait rapidement devenir coûteux pour le propriétaire du site Web.
Extraction d’une page sur indeed
Vous pouvez utiliser n’importe quel autre site Internet que vous pouvez consulter, mais la difficulté de le faire dépend du site. Ce tutoriel vous propose une introduction au scraping Web pour vous aider à comprendre le processus globalement. Par ailleurs, vous pouvez appliquer ce même processus pour chaque site Web dont vous souhaitez extraire des données.
Étape 1: Recherche de l'URL à extraire
Dans ce didacticiel, nous allons extraire des données du site d’agrégation d’emplois indeed.
- Déchiffrez les informations dans les URL : De nombreuses informations peuvent être encodées dans une URL. Votre parcours de scraping Web sera beaucoup plus facile si vous vous familiarisez d’abord avec le fonctionnement des URL et leur composition. Essayez de distinguer l’URL du site sur lequel vous vous trouvez actuellement:
Ex: https://fr.indeed.com/emplois?q=Machine+Learning&l=France
Vous pouvez décompose l’URL ci-dessus en deux parties principales:
- L’URL de base représente le chemin d’accès à la fonctionnalité de recherche du site Web. Dans l’exemple ci-dessus, l’URL de base est https://fr.indeed.com/emplois.
- Les paramètres de requête représentent des valeurs supplémentaires qui peuvent être déclarées sur la page. Dans l’exemple ci-dessus, les paramètres de requête sont
?q=Machine+Learning&l=France.
Tout emploi que vous recherchez sur ce site Web utilisera la même URL de base. Cependant, les paramètres de requête changeront en fonction de ce que vous recherchez. Vous pouvez les considérer comme des chaînes de requête qui sont envoyées à la base de données pour récupérer des enregistrements spécifiques.
Les paramètres de requête se composent généralement de trois éléments:
- Début: le début des paramètres de la requête est indiqué par un point d’interrogation (?).
- Information: les éléments d’information constituant un paramètre de requête sont codés en paires clé-valeur, où les clés et les valeurs associées sont jointes par un signe égal (q = valeur).
- Séparateur: chaque URL peut avoir plusieurs paramètres de requête, séparés les uns des autres par une esperluette (&).

Muni de ces informations, vous pouvez séparer les paramètres de requête de l’URL en deux paires clé-valeur:
q = Machine Learning –> sélectionne le type d’emploi que vous recherchez.
où = France –> sélectionne le lieu que vous recherchez.Machine Learning
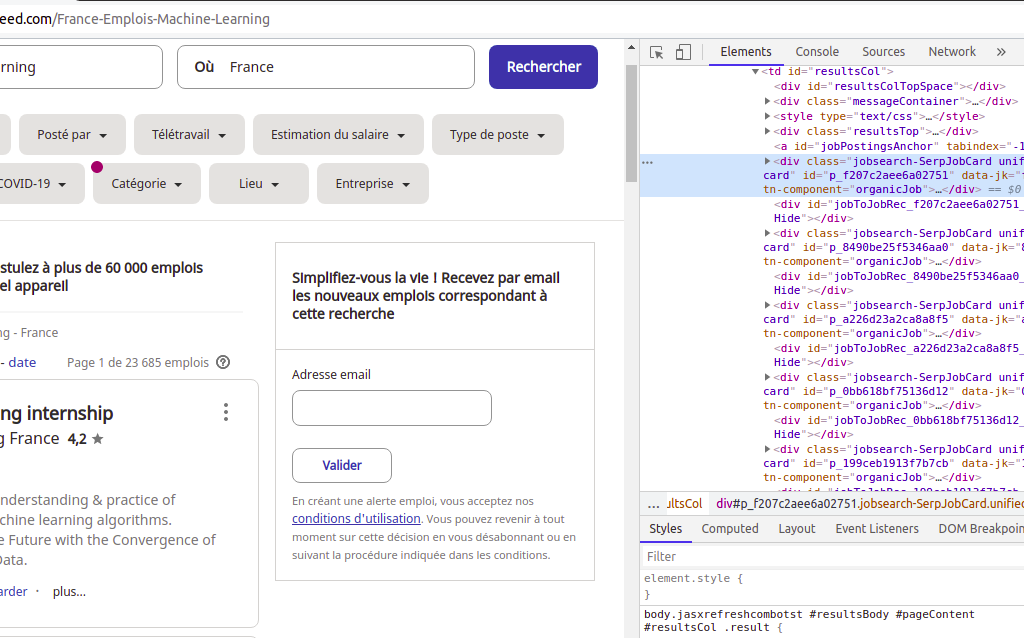
Etape 2: Inspection de la source de données
Vous devez savoir plus sur la façon dont les données sont structurées pour les affichages. Les données sont généralement imbriquées dans des balises. Nous allons donc inspecter la structure de la page pour voir sous quelle balise les données que nous voulons extraire sont imbriquées. Pour inspecter la page, faites un clic droit sur l’élément et cliquez sur «Inspecter».
Etape 3: Chargement des pages Web avec "request"
Sur le Web, les serveurs et les clients communiquent généralement via des requêtes HTTP.
HTTP signifie «HyperText Transfer Protocol» et spécifie comment les demandes et les réponses doivent être formatées et transmises. Il s’agit en général de la méthode utilisée pour les demandes lors de la navigation sur le web.
Le navigateur envoie une requête au serveur de cette page, et le serveur répond avec les ressources pertinentes (HTML, images, etc.).
Les deux types de requêtes les plus courants sont GET et POST.
GET
- Obtenir des données du serveur
- Peut être ajouté à vos favoris
- Les paramètres sont ajoutés directement dans l’URL
- Non utilisé pour envoyer des informations sensibles (telles que mots de passe)
POST
- Habituellement utilisé lorsqu’un état doit être modifié (comme l’ajout d’articles à vos panier sur un site e-commerce) ou lors de l’envoi de mots de passe
- Les paramètres sont ajoutés dans un corps séparé, donc c’est plus sûr
Pour cette tâche, Nous allons utiliser la bibliothèque de requêtes de Python. Pour l’installer, lancer un terminal et taper la commande :
pip install requests
import requests
base_site = 'https://fr.indeed.com/France-Emplois-Machine-Learning'
response = requests.get(base_site)
response.status_code
La réponse contient 2 informations principales: le code d’état et le corps de la réponse. Le code d’état indique si la demande a abouti et / ou des erreurs. Il est représenté par un nombre à 3 chiffres.
Les codes dans les plages indiquent:
- 2xx – Succès
- 3xx – Redirections
- 4xx – Erreurs client
- 5xx – Erreurs de serveur
Les deux codes d’état les plus fréquemment rencontrés sont:
- 200 OK – La demande a réussi
- 404 Not Found – Le serveur ne trouve pas le fichier demandé
Etape 4: Créer un objet Beautiful Soup
Beautiful Soup est une bibliothèque Python permettant d’analyser des données structurées. Il vous permet d’interagir avec HTML d’une manière similaire à la façon dont vous interagissez avec une page Web à l’aide des outils de développement.
Pour commencer, utilisez votre terminal pour installer la bibliothèque Beautiful Soup Via la commande :
pip install beautifulsoup4
Beautiful Soup est une bibliothèque Python permettant d’extraire des données d’un document HTML. Il y parvient en analysant le HTML avec un analyseur syntaxique.
Analyseurs pris en charge de Beautiful Soup:
- Html.parser: Est l’analyseur python intégré, c’est un analyseur correct et ne nécessite pas d’installation. Cependant il fait parfois des erreurs, c’est pourquoi il est considéré comme le pire analyseur.
- Lxml: C’est très rapide et c’est le seul analyseur XML pour Beautiful Soup. Il nécessite une installation, et il fait partie de la distribution anaconda. C’est le meilleur analyseur pour Beautiful Soup.
- Html5lib: C’est un package Python qui implémente l’algorithme d’analyse HTML5 qui est fortement influencé par les navigateurs actuels et basé sur la spécification WHATWG HTML5. C’est le plus lent. Cependant, c’est l’analyseur le plus cohérent et qui peut gérer du HTML très mal écrit. Il fait partie de la distribution anaconda.
from bs4 import BeautifulSoup #importer la bibliothèque BeautifulSoup
# obtenir le code HTML de la page Web
html = response.content
# convertir le HTML en objet BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
Etape 5: Extraction des informations
Nous allons extraire les informations suivantes:
- Titre
- Nom de l’entreprise
- Localisation
- Durée de la publication
Recherche de toutes les instances d'un tag à la fois
Trouvez la classe de la balises div englobant chaque publication.
Par inspection on voir que la classe de la balise englobante de chaque publication est la classe jobsearch-SerpJobCard
Nous allons utiliser la méthode find_all pour rechercher des éléments par classe de la balise englobant chaque poste.
# Trouvez les balises div englobantes jobsearch-SerpJobCard
divs = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
Notez que find_all renvoie une liste, nous devrons donc la parcourir ou utiliser l’indexation de liste pour extraire le texte:
Récupération des titres
# Les titres sont dans une balise h2 avec la classe 'title'
titres = [div.find("h2", {"class": "title"}) for div in divs]
titres[0]# Inspection d'un élément
<h2 class= »title »>
<a class= »jobtitle turnstileLink » data-tn-element= »jobTitle » href= »/rc/clk?jk=0bb618bf75136d12&fccid=f8603cd018550c8d&vjs=3″ id= »jl_0bb618bf75136d12″ onclick= »setRefineByCookie([]); return rclk(this,jobmap[0],true,0); » onmousedown= »return rclk(this,jobmap[0],0); » rel= »noopener nofollow » target= »_blank » title= »Data Analyst – Machine Learning (H/F) »>
Data Analyst – <b>Machine</b> <b>Learning</b> (H/F)</a> </h2>
'''Par inspection, nous voyons que la chaîne que nous recherchons
se trouve dans la balise "title" du deuxième enfant de la balise 'div' '''
titres[3].contents[1]['title']
Ingénieur.e « Data scientist » (Computer Vision et Deep Learning)
# Extraction de la chaîne
titres_clean = [titre.contents[1]['title'] for titre in titres]
titres_clean
Récupérations des noms des entreprises
# Le nom de l’entreprise et la localisation peuvent être trouvés dans un div avec la classe 'sjcl'
sjcl_data = [div.find("div", {"class": "sjcl"}) for div in divs]
sjcl_data[0] # Inspection d’un element
companies = [sjcl_data[i].contents[1] for i in range(len(sjcl_data))]
companies[1]#Inspection d'un élément
compagny_name = companies[0].contents[1]
compagny_name.get_text()
\n\nSAP
# Extraction de la chaîne
compagny_names = [entreprise.contents[1].get_text().strip('\n\n') for entreprise in companies]
compagny_names
Récupérations des nom des localisations
localisations = [sjcl_data[i].contents[5].get_text() for i in range(len(sjcl_data))]
localisations
Récupérations des durées de la publication
# Les durées peuvent être trouvés dans un div avec la classe 'result-link-bar'
dates = [div.find("div", {"class": "result-link-bar"}) for div in divs]
dates[10].contents[0].get_text() #Afficher une dates
il y a 1 jour
dates[6].contents[0].get_text()
Il y a plus de 30\xa0jours
#Extractions des dates
dates_list = [] # creer une liste vide
/n
for i in range(len(dates)):
'''Ajouter les dates dans la liste'''
dates_list.append(dates[i].contents[0].get_text())
dates_list #Afficher les dates
Nous allons enlever les « \xa0 »
date_first_clean = [date.strip('\xa0jours') for date in dates_list]
date_second_clean = [date for date in date_first_clean if date.lower().startswith('il')]
date_first_clean
Nous allons ajouter les « jours »
date_last_clean = [] '
for date in date_clean:
if date in date_clean1:
date_last_clean.append(date + ' jours')
else:
date_last_clean.append(date)
date_last_clean
Combinaison de nos données dans une trame de données Pandas
Nous allons combiner les données dans un DataFrame. Un DataFrame est un objet qui peut stocker des données tabulaires, ce qui facilite l’analyse des données.
Pour cette tâche, Nous allons utiliser la bibliothèque Pandas. Pour l’installer, lancer un terminal et taper la commande :
pip install pandas
import pandas as pd # importer la bibliothèque pandas
job_post = pd.DataFrame()# créer un dataframe
Nous allons ajouter les données dans le dataframe
job_post['Titre'] = titres_clean
job_post['Entreprise'] = entreprise_clean
job_post['Localisation'] = localisations
job_post['Duree'] = date_clean
job_post.shape #Dimensions de notre DataFrame
(15, 4)
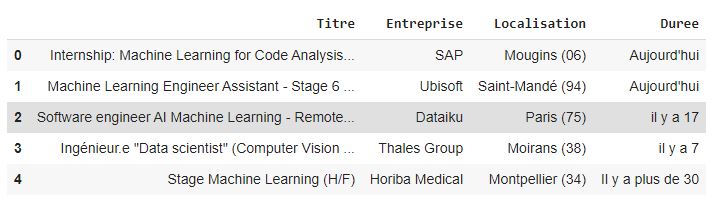
job_post.head() #Visualisons les 5 premier lignes
Conclusion
Le scraping Web est le processus de collecte d’informations sur Internet.
L’un des défis que vous rencontreriez en récupérant des informations sur des sites Web concerne les différentes structures des sites Web. Cela signifie que les modèles de sites Web seront différents et seront uniques; par conséquent, la généralisation sur les sites Web pourrait être un défi.
Dans ce tutoriel, vous avez appris à extraire des données du Web à l’aide de Python, des requêtes et de Beautiful Soup. J’espère que ce tutoriel vous a aidé à comprendre les bases du web scraping avec Python.