
Par définition, Edge Computing est une architecture informatique destinée aux environnements IoT, où les ressources informatiques, la capacité de stockage et la puissance de calcul sont maintenues au plus près des équipements terminaux et des capteurs générant des données. Ce concept représente ainsi une alternative aux solutions de Cloud ordinaires avec des serveurs centralisés.
D’après les multiples études menées par des grandes entreprises dans le domaine, en 2021 l’Internet des objets (IoT) qui définit l’interconnexion des systèmes électroniques, du pèse-personne électronique jusqu’aux sites de production industrielle, devrait inclure plus de 30 milliards d’objets connectés dans le monde entier. Tous ces objets génèrent des données en continu, qui nécessitent d’être stockées et évaluées en temps réel pour des applications critiques. Ceci représente une tâche que les solutions Cloud ne seront pas en mesure de maîtriser.
Ce qui risque de freiner ce développement est avant tout la question du déploiement des réseaux à haut débit, ainsi que les temps de latence dans le transfert des données entre les serveurs Cloud centraux et les équipements terminaux en périphérie du réseau. L’edge computing évite ces deux problèmes et introduit de cette manière un changement de paradigme dans l’univers du Cloud computing.
L’Edge Computing, c’est quoi ?
Par définition, Edge Computing est une architecture informatique destinée aux environnements IoT, où les ressources informatiques, la capacité de stockage et la puissance de calcul sont maintenues au plus près des équipements terminaux et des capteurs générant des données. Ce concept représente ainsi une alternative aux solutions de Cloud ordinaires avec des serveurs centralisés.
Le mot « edge » vient de l’anglais et signifie bord ou périphérie. Ce terme fait allusion au fait que le traitement des données ne se fait plus dans le Cloud, mais il est décentralisé, en périphérie du réseau. L’edge computing offre ainsi une option que le Cloud n’est pas capable de proposer, à savoir des serveurs capables d’interpréter sans délai les données de masse générées par des usines, des réseaux de distributions ou des systèmes de circulation « intelligents », et de prendre immédiatement les mesures nécessaires en cas d’incidents.
Présentation des fondamentaux de l’Edge Computing
L’edge computing est une nouvelle forme d’architecture pour les environnements IoT bien qu’elle n’ait pas directement recours à de nouveaux composants de réseau. Au contraire, elle s’appuie sur d’anciennes technologies dans un format compact, mais employées sous une nouvelle dénomination. Voici un aperçu des éléments de base de l’edge computing.
- L’Edge Computing est une nouvelle forme d’architecture pour les environnements IoT bien qu’elle n’ait pas directement recours à de nouveaux composants de réseau. Au contraire, elle s’appuie sur d’anciennes technologies dans un format compact, mais employées sous une nouvelle dénomination. Voici un aperçu des éléments de base de l’edge computing.
- Edge device : on entend par edge device tout appareil situé en périphérie de réseau, et qui génère des données. Les sources de données possibles sont par exemple des capteurs, des machines, des véhicules ou tous les autres appareils intelligents dans un environnement IoT, comme des lave-linge, des détecteurs d’incendie, des ampoules ou des thermostats pour radiateur.
- La passerelle Edge : la passerelle Edge est une instance de calcul implantée à la transition entre deux réseaux. Dans des environnements IoT, les passerelles Edge sont utilisées comme nœuds entre l’Internet des objets et le réseau central. On a aussi de puissants routeurs, capables de supporter de fortes puissances de calcul pour assurer le traitement des données de l’IoT. Pour ce faire, les passerelles Edge disposent de diverses interfaces permettant de transférer les données soit par câble, soit par radio, et de standards de communication, comme l’Ethernet, le Wifi, le Bluetooth, la téléphonie 3G, LTE, Zigbee, Z-Wave, CAN-Bus, Modbus, BACnet ou SCADA.
L’Edge Computing vs. le Fog Computing
L’approche visant à étendre le Cloud autour des instances de calcul n’est pas une nouveauté. En 2014 déjà, le groupe américain Cisco a créé le terme marketing, baptisé « Fog Computing». Ce concept est basé sur un traitement décentralisé des données dans ce qu’on appelle des « nœuds fogs ». Les nœuds fog représentent de mini-centres de calcul positionnés en amont du Cloud, constituant une couche intermédiaire dans le réseau (on parle de « couche fog »). Les données générées dans des environnements IoT ne sont donc pas directement envoyées dans le Cloud. Elles sont d’abord collectées dans des Fog Notes, où elles sont interprétées avant d’être sélectionnées pour d’autres formes de traitement.
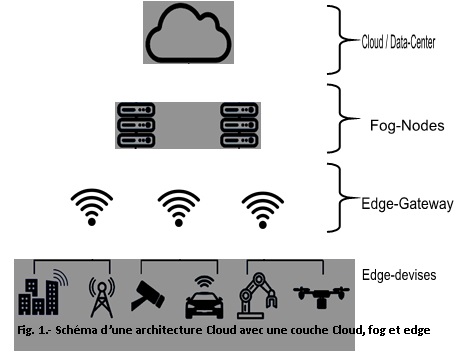
L’edge computing est aujourd’hui considéré comme faisant partie du Fog Computing, où les ressources informatiques, comme la puissance de calcul et la capacité de stockage sont rapprochées au mieux des équipements IoT, en périphérie du réseau. Dans des architectures de fog computing, le traitement des données se fait d’abord au niveau de la couche fog, tandis que dans des concepts d’edge computing, il est exécuté au niveau de puissants routeurs IoT, et même parfois directement sur les appareils ou sur les capteurs. On peut parfaitement envisager une combinaison des deux concepts. Le graphique (Fig. 1.-) ci-dessous montre une telle architecture avec une couche Cloud, fog et edge.
Pourquoi l’Edge Computing ?
Une tour de forage génère 500 gigaoctets de données par semaine. La turbine d’un avion de ligne en fournit 10 téraoctets en 30 minutes. Les réseaux mobiles ne permettent pas de télécharger ni de traiter des données d’un tel volume, ni dans le Cloud, ni en temps réel. Vient s’ajouter le fait que le recours à des réseaux tiers est un élément très coûteux. Il faut donc décider sur place quelles informations générées doivent être transférées vers des systèmes centralisés pour y être enregistrées, et quelles données peuvent être interprétées sur place. C’est là que l’edge computing entre en jeu.
De nos jours, ce sont les grands centres de données qui supportent l’essentiel du volume des données générées par Internet. Les sources de données sont pourtant très souvent mobiles, et trop éloignées des gros ordinateurs centraux pour pouvoir garantir un délai de latence satisfaisant. Ce facteur pose problème, en particulier pour les applications critiques comme l’apprentissage automatique et la « maintenance prévisionnelle1 », deux concepts de base du projet allemand Industrie 4.0 par exemple avec des sites de production intelligents et des réseaux de distribution auto-régulés.
Même l’internet à usage domestique comme le streaming de vidéos à haute résolution sur des appareils mobiles, la réalité virtuelle et la réalité augmentée mettent en péril les concepts de Cloud classiques, ainsi que la bande passante des réseaux existants. Avec une vitesse de transfert pouvant atteindre les 10 Go/s, la mise en œuvre du nouveau réseau mobile 5G ne devrait pas régler le problème du volume croissant des données, mais plutôt l’accentuer, à en croire les experts en la matière. L’edge computing n’est pas non plus la solution à ce problème. Le concept pose cependant bien la question de savoir si toutes les données d’un environnement IoT doivent bel et bien être traitées dans le Cloud.
Dans cette première partie de cet article, nous venons de voir c’est quoi l’Edge Computing, ses différences et ses points communs avec le Fog Computing et à quoi sert vraiment l’Edge Computing. Maintenant, nous vous donnons rendez-vous pour la deuxième partie de l’article dans un autre numéro du blog. Merci.
Votre commentaire