
La régression linéaire est une modélisation linéaire qui permet d’établir des estimations dans le futur à partir d’informations provenant du passé. Dans ce modèle de régression linéaire, on a plusieurs variables dont une qui est une variable explicative et les autres qui sont des variables expliquées. Les bénéfices, les ventes, les taux hypothécaires, la valeur des maisons, la superficie en pieds carrés, la température ou la distance peuvent être prédits à l’aide de techniques de régression. Par exemple, on peut prédire le prix d’une voiture à partir de quelques informations de la voiture, ou expliquer les performances d’un athlète par la durée de son entraînement ou même le salaire d’une personne par le nombre d’années passées à l’université.
Dans cet article, nous allons expérimenter la régression linéaire en créant un modèle pour prédire le prix d’une automobile. Pour ce faire, nous allons fournir au modèle une description de nombreuses automobiles de cette période. Cette description prend des attributs tels que: Marque, Prix, Carrosserie, Kilométrage, Moteur V, Type de moteur, Immatriculation, Année, et Modèle de la voiture.
Formule de la droite de régression linéaire
Formule de la droite de régression linéaire
Y= ß0+ß1×1+ß2×2+e
● Y correspond à la variable dépendante
● x1 et x2 correspondent aux variables explicatives
● e correspond à l’erreur d’estimation
● ß0 ß1 et ß2 correspondent aux coefficients qui permettent de réduire l’erreur e
Pour obtenir une analyse de régression linéaire efficace il ya des hypothèse prendre en compte :
Données : Les variables dépendantes et indépendantes doivent être quantitatives.
Homoscédastique: Pour chaque valeur de la variable indépendante, la distribution de la variable dépendante doit être normale. La variance de la distribution de la variable dépendante doit être constante pour toutes les valeurs de la variable indépendante.
Linéarité: La relation entre la variable dépendante et chaque variable indépendante doit être linéaire et toutes les observations doivent être indépendantes.
L’ensemble de données
Vous pouvez télécharger l’ensemble de données sur ce lien
Importation des bibliothèques
Pour cette exemple pratique nous aurons besoin des bibliothèques suivants:
from sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
import statsmodels.api as sm
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
sns.set()Charger les données d’un fichier .csv dans le même dossier
raw_data = pd.read_csv('1.04. Real-life example.csv')
# Explorons les 5 premières lignes du df(DataFrame)
raw_data.head()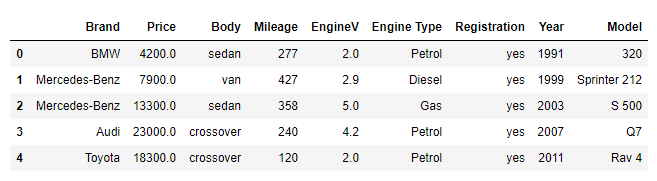
# Dimesnion de notre ensemble de donnees
raw_data.shape
(4345, 9)Comme on peut le voir, notre ensemble de données contient 4345 lignes et 9 colonnes. Mais, nous allons seulement utiliser une partie de l’ensemble de données. Vous pouvez utiliser la méthode sample(), ou la méthode iloc[]. sample(): La méthode sample() renvoie une liste avec une sélection aléatoire d’un nombre spécifié d’éléments d’une séquence. iloc: La méthode iloc vous permet de « localiser » une ligne ou une colonne par son « index entier ».
Importation des bibliothèques
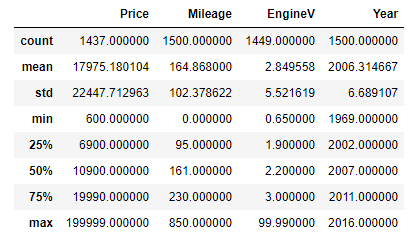
Description statistiques de quelques variables
Les statistiques descriptives sont très utiles pour l’exploration initiale des variables. Lorsqu’on fait dataset.describe() seuls les descriptifs des variables numériques sont affichés.
Nous allons sélectionner la colonne « Marque » pour l’axe des x et le nombre de voitures vendues pour l’axe des y, qui est la «hauteur».
Pour inclure les catégories, on doit spécifier avec un argument dataset.describe(include=’all’).

Notez que les variables catégorielles n’ont pas certains types de descriptions numériques et queles variables numériques n’ont pas certains types de descriptifs catégoriels.
Gérer les valeurs manquantes
data.isnull()
●data.isnull(): montre un dataFrame avec les informations si un point de données est nul ou pas.
● True: le point de données est manquant
● False: le point de données n’est pas manquant
Nous pouvons les additionner cela nous donnera le nombre total de valeurs manquantes en fonction des fonctionnalités
# afficher le nombre de valeurs manquantes
data.isnull().sum()
D’après le résultat, les variables Price et EngineV on des valeurs null. Il existe plusieurs méthodes pour traiter les valeurs null, l’une d’entre elles est d’utiliser la classe SimpleImputer ou IterativeImputer de la bibliothèque Scikit-learn.Nous allons seulement supprimer les valeurs null dans notre cas. Ce n’est pas toujours recommandé de supprimer les valeurs null, cependant si les valeurs null représentent moins de 5% du l’ensemble de données ce n’est pas un problème considérable.
# Visualisation des cinq premières ligne
dataset.head()Vérifier s’il existe des lignes en double
Il existe une fonction intégrée dans Pandas qui trouve les lignes en double en fonction de toutes les colonnes ou de certaines colonnes spécifiques. La fonction pandas.duplicated() renvoie une série booléenne avec une valeur True pour chaque ligne dupliquée.
# Trouver des lignes en double
duplicateDFRow = data_no_mv[data_no_mv.duplicated()]
print(duplicateDFRow)Nous allons sélectionner la colonne « Marque » pour l’axe des x et le nombre de voitures vendues pour l’axe des y, qui est la «hauteur».

Nous avons des lignes en doublon comme on peut le remarquer.
# Supprimer les lignes en doublon
data_no_mv.drop_duplicates(keep='last', inplace = True)
# Trouver des lignes en double
duplicateDFRow = data_no_mv[data_no_mv.duplicated()]
print(duplicateDFRow)Plus de ligne en doublon dans notre ensemble de données
Explorer les PDF
Une grande étape dans l’exploration des données consiste à afficher la fonction de distribution de probabilité (PDF) d’une variable. Le PDF nous montrera comment cette variable est distribuée cela permet de repérer très facilement les anomalies, telles que les valeurs aberrantes. Le PDF est souvent la base sur laquelle nous décidons si nous voulons transformer une fonctionnalité.
_, ax = plt.subplots(figsize=(15, 8))
sns.distplot(data_no_mv['Price'])
_, ax = plt.subplots(figsize=(15, 8))
sns.histplot(data['Mileage'], kde=True, bins=200)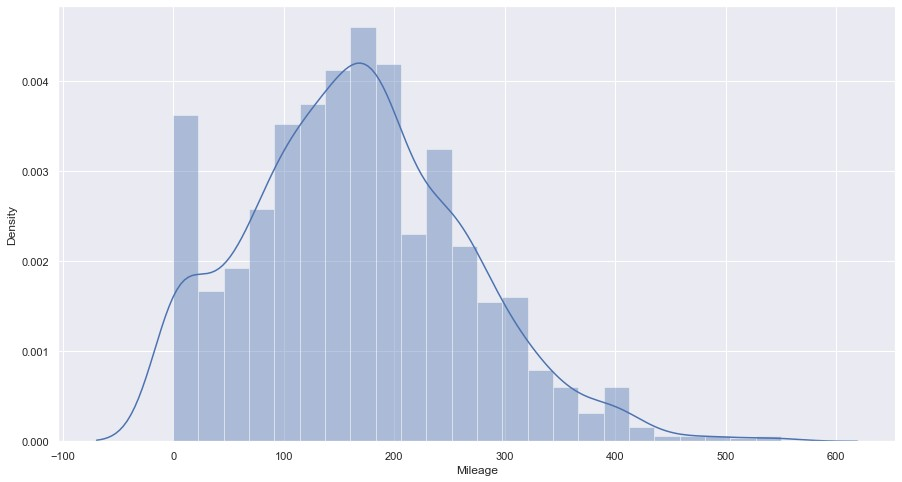
_, ax = plt.subplots(figsize=(15, 8))
sns.distplot(data_no_mv['EngineV'])
_, ax = plt.subplots(figsize=(15, 8))
sns.distplot(data_no_mv['Year'])
Il y a évidemment des valeurs aberrantes
Traiter les valeurs aberrantes
Ici, les valeurs aberrantes se situent autour des prix les plus élevés (côté droit du graphique) La logique doit également être appliquée Ceci est un ensemble de données sur les voitures d’occasion, donc on peut imaginer à quel point 200 000 $ est un prix excessif. Nous pouvons traiter le problème facilement en supprimant 0,5%, ou 1% des échantillons problématiques.
Les valeurs aberrantes sont un problème majeur pour les OLS, nous devons donc les gérer d’une manière ou d’une autre Il peut être utile d’essayer d’entraîner un modèle sans supprimer les valeurs aberrantes Déclarons une variable qui sera égale au 99ème centile de la variable ‘Prix’
# Déclarons une variable qui sera égale au 99e centile de la variable
'Prix'
q = data['Price'].quantile(0.99)
# Ensuite, nous pouvons créer un nouveau df, à la condition que tous les
prix soient inférieurs au 99 centile de « Prix »
df1 = data[data['Price']<q]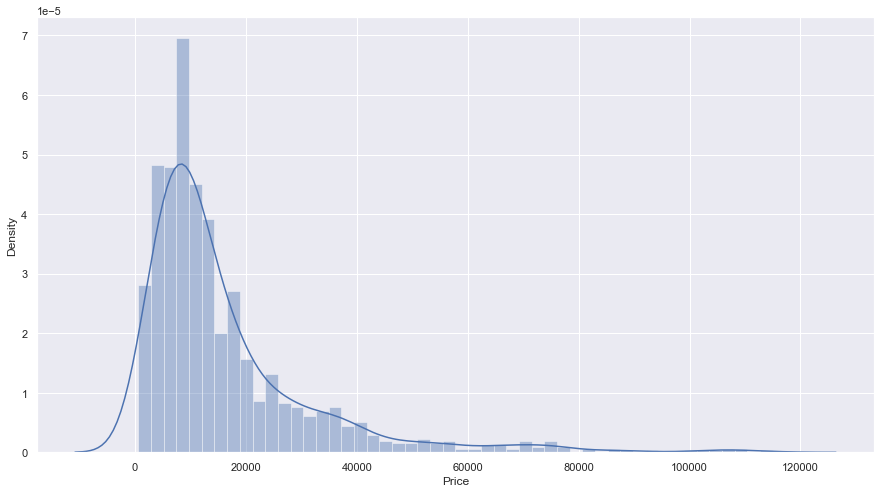
_, ax = plt.subplots(figsize=(15, 8))
sns.distplot(data_no_mv['Mileage'])
On va garder les voiture qui ont une volumes de moteur inférieur ou égal a 8l
data_3 = data_2[data_2['EngineV']<=8]
sns.distplot(data_3['EngineV'])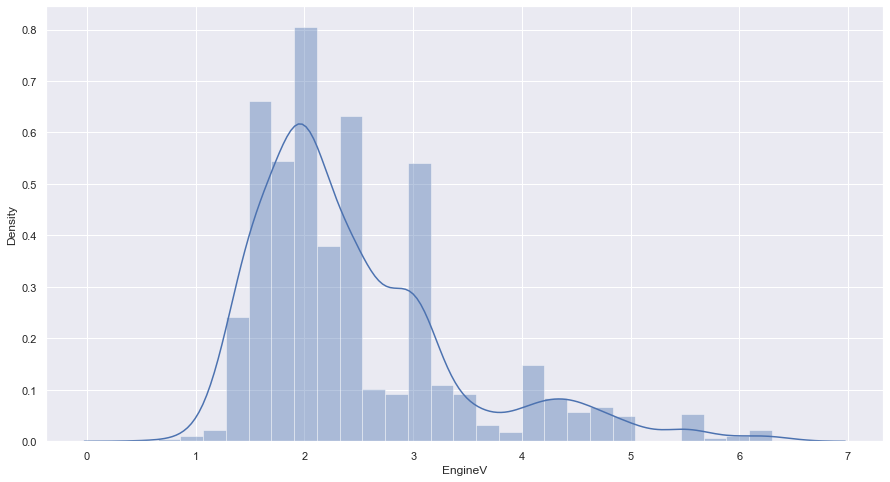
La situation avec « Année » est similaire à « Prix » et « Kilométrage ». Cependant, les valeurs aberrantes sont au bas de l’échelle.
# Supprimons les valeurs aberrantes
q = data_3['Year'].quantile(0.01)
data_4 = data_3[data_3['Year']>q]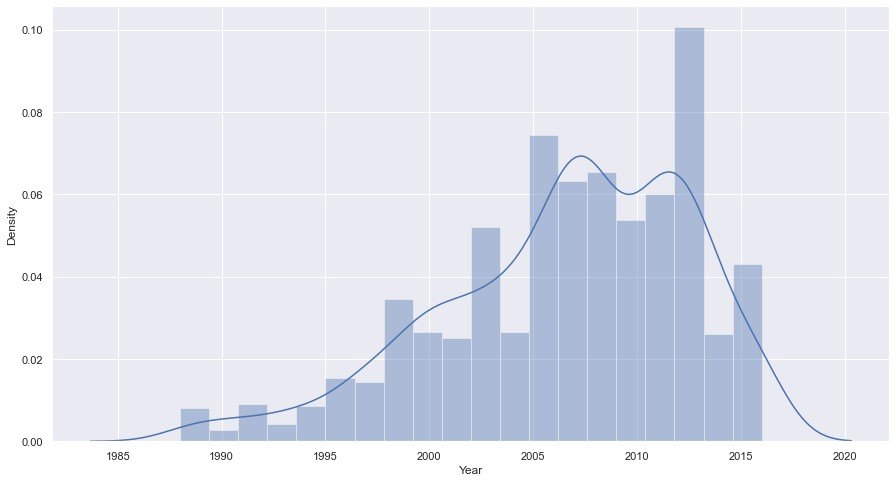
Une fois l’index réinitialisé, une nouvelle colonne sera créée contenant l’ancien index. Nous allons l’oublier complètement.
data_cleaned = data_4.reset_index(drop=True)Vérification des hypothèses OLS (Ordinary Least Squares)
La violation de ces hypothèses peut réduire la validité des résultats produits par le modèle. OLS fonctionne dans une assez grande variété de circonstances différentes. Cependant, certaines hypothèses doivent être satisfaites afin de garantir que les estimations sont normalement distribuées dans de grands échantillons comme la linéarité, pas de multicolinéarité, pas d’autocorrélation, homoscédasticité, distribution normale des erreurs (nous en discuterons dans un nouveau article). L’hypothèse que nous allons voir est la linéarité. Cette hypothèse stipule que la relation entre la variable dépendante et la variable indépendante doit être linéaire. Vous pouvez simplement utiliser plt.scatter() pour chacun d’eux (avec vos connaissances actuelles). Mais comme Price est l’axe ‘y’ de tous les graphiques, il était logique de les tracer côte à côte (afin que nous puissions les comparer)
f, (ax1, ax2, ax3) = plt.subplots(1, 3, sharey=True, figsize =(15,3))
ax1.scatter(data_cleaned['Year'],data_cleaned['Price'])
ax1.set_title('Price and Year')
ax2.scatter(data_cleaned['EngineV'],data_cleaned['Price'])
ax2.set_title('Price and EngineV')ax3.scatter(data_cleaned['Mileage'],data_cleaned['Price'])
ax3.set_title('Price and Mileage')
plt.show()
plt.figure(figsize=(120,5))
for i, col in enumerate(data_cleaned[['Year','Mileage']].columns):
plt.subplot(1, 13, i+1)
# initialiser les data column
x = data_cleaned[col]
y = data_cleaned['Price']
# Donner les parametres correspondant aux abscises et ordonnees
plt.plot(x, y, 'o')
# Creation de la ligne de regression
plt.plot(np.unique(x), np.poly1d(np.polyfit(x, y, 1))(np.unique(x)))
plt.title(col)
plt.xlabel(col)
plt.ylabel('Prix')
Nous pouvons clairement voir un motif dans le tracé indiquant la non-linéarité. Un tracé idéal aura les résidus répartis également autour de la ligne horizontale.
À partir des sous-parcelles et du PDF du prix, nous pouvons facilement déterminer que le « Prix » est distribué de manière exponentielle. Une bonne transformation dans ce cas est une transformation log.
# Transformons 'Prix' avec une transformation log
log_price = np.log(data_cleaned['Price'])
# Ensuite, nous l'ajoutons à notre bloc de données
df1.loc[:, 'log_price'] = log_price
df1.head()Étant donné que nous utiliserons la variable Price dans l’ensemble de données, nous pouvons supprimer l’ancienne ‘Prix’
data_cleaned = data_cleaned.drop(['Price'],axis=1)
# Vérifions à nouveau les trois scatters
f, (ax1, ax2, ax3) = plt.subplots(1, 3, sharey=True, figsize =(15,3))
ax1.scatter(data_cleaned['Year'],data_cleaned['log_price'])
ax1.set_title('Log Price and Year')
ax2.scatter(data_cleaned['EngineV'],data_cleaned['log_price'])
ax2.set_title('Log Price and EngineV')
ax3.scatter(data_cleaned['Mileage'],data_cleaned['log_price'])
ax3.set_title('Log Price and Mileage')
plt.show()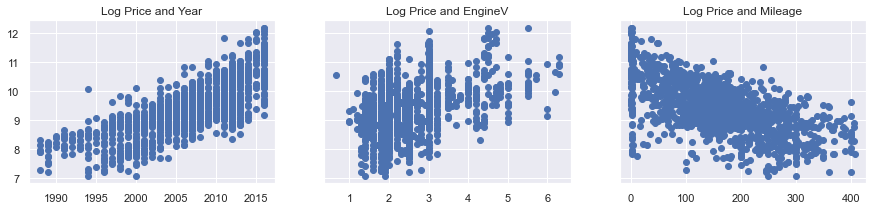
plt.figure(figsize=(120,5))
for i, col in enumerate(data_cleaned[['Year','Mileage',
'EngineV']].columns):
plt.subplot(1, 13, i+1)
# initialiser les data column
x = data_cleaned[col]
y = data_cleaned['log_price']
# Donner les parametres correspondant aux abscises et ordonnees
plt.plot(x, y, 'o')
# Creation de la ligne de regression
plt.plot(np.unique(x), np.poly1d(np.polyfit(x, y, 1))(np.unique(x)))
plt.title(col)
plt.xlabel(col)
plt.ylabel('Prix')
Les relations montrent une relation linéaire claire. Alternativement, nous aurions pu transformer chacune des variables indépendantes
Multicolinéarité
La multicolinéarité se produit lorsque les variables indépendantes sont fortement corrélées, c’est-à- dire que les variables indépendantes dépendent les unes des autres. La multicolinéarité est un gros problème mais c’est aussi la plus facile à remarquer. Avant de créer la régression, recherchez la corrélation entre chacune des deux paires de variables indépendantes. Pour détecter l’impact de la multiculturalité entre les variables, nous pouvons utiliser le facteur d’inflation de la variance (VIF). Si le VIF est élevé pour une variable indépendante, il y a une chance qu’il soit déjà expliqué par une autre variable. Les variables indépendantes avec une valeur VIF supérieure à 10 peuvent être corrélées.
sklearn n’a pas de moyen intégré pour vérifier la multicolinéarité, l’une des principales raisons est qu’il s’agit d’un problème bien couvert dans les cadres statistiques et non dans ceux du ML.
Cependant, nous pouvons utiliser statsmodels. statsmodels est un module Python qui fournit des classes et des fonctions pour l’estimation de nombreux modèles statistiques différents, ainsi que pour la réalisation de tests statistiques et l’exploration de données statistiques. Les résultats sont testés par rapport aux progiciels statistiques existants pour s’assurer qu’ils sont corrects.
Nous allons utiliser le variance_inflation_factor, qui affichera essentiellement les FIV respectifs, puis inclure des noms pour que le résultat soit plus facile a explorer.
# importer la fonction variance_inflation_factor du module
outliers_influence
from statsmodels.stats.outliers_influence import variance_inflation_factorNous allons créer un nouveau DataFrame qui comprendra tous les FIV (facteur d’inflation de variance) notez que chaque variable a son propre facteur d’inflation de variance car cette mesure est spécifique à la variable (non spécifique au modèle)
fiv = pd.DataFrame()
varables = data_cleaned[['Year','Mileage', 'EngineV']]
fiv["FIV"] = [
variance_inflation_factor(
varables.values, # matrice de conception avec toutes les variables
explicativesi # indice de la variable idependante dans les colonnes de la
matrice
) for i in range(varables.shape[1])]
fiv["Features"] = varables.columns
# Explorons le résultat
fiv
si VIF est supérieur à 5, la variable explicative donnée par i est fortement colinéaire avec les autres variables explicatives, et les estimations de paramètres auront de grandes erreurs standard à cause de cela.
Étant donné que l’année a le VIF le plus élevé, on peut le supprimer du modèle
data_no_multicollinearity = data_cleaned.drop(['Year'],axis=1)
fiv_2 = pd.DataFrame()
varables_ = data_cleaned[['Year','Mileage']]
fiv_2["FIV"] = [
variance_inflation_factor(
varables_.values, # matrice de conception avec toutes les
variables explicatives
i # indice de la variable idependante dans les colonnes de la
matrice
) for i in range(varables_.shape[1])]
fiv_2["Features"] = varables_.columns
fiv_2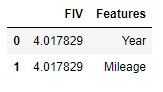
Multicolinéarité
Pour inclure les données catégorielles dans la régression, il existe plusieur méthodes, telles que:
● Remplacer les valeurs: Cette méthode consiste simplement à remplacer les valeurs catégorielles par les nombres souhaités. Ceci peut être réalisé à l’aide de la fonction replace() dans pandas. L’avantage de cette méthode c’est que vous avez la liberté de choisir les numéros que vous souhaitez attribuer aux valeurs catégorielles en fonction du cas d’utilisation métier.
● Label Encoder: Il est utilisé pour transformer des étiquettes non numériques en étiquettes numériques (ou variables catégorielles nominales)
● Dummy Coding: C’est une méthode couramment utilisée pour convertir une variable d’entrée catégorielle en variable continue. « Dummy », comme son nom l’indique, est une variable en double qui représente un niveau d’une variable catégorielle. La présence d’un niveau est représentée par 1 et l’absence est représentée par 0.
● One Hot Encoding: Il s’agit de diviser la colonne qui contient des données catégorielles numériques en plusieurs colonnes en fonction du nombre de catégories présentes dans cette colonne. Chaque colonne contient « 0 » ou « 1 » correspondant à la colonne dans laquelle elle a été placée.
Dans le cas où vous avez un niveau de variables trop élevé vous pouvez essayer d’abord de réduire les niveaux en utilisant des méthodes de combinaison, puis d’utiliser le « Dummy Coding ». Cela vous ferait gagner du temps. Dans notre cas, nous allons utiliser le « Dummy Coding ». Il est extrêmement important que nous abandonnions l’un des variables indicatrices, sinon nous introduisons la multicolinéarité.
# Nous allons creer nitre modele sans la colonne model
dataset = data_no_multicollinearity.drop(['Model'], axis=1)
data_with_dummies = pd.get_dummies(dataset, drop_first=True)
# La variable cible (variable dépendante) est le « log_price »
targets = data_with_dummies['log_price']# Les entrées sont tout les autres variables, nous pouvons donc simplement
la supprimer
inputs = data_with_dummies.drop(['log_price'],axis=1)
Mettez à l'échelle les caractéristiques et stockez-les dans une nouvelle variable
x_ = PolynomialFeatures(degree=2,
include_bias=False).fit_transform(inputs)
# Divisez les variables avec une division 80-20 et un état aléatoire
X_train, X_test, Y_train, Y_test = train_test_split(x_, targets,
test_size=0.20, random_state=200)
# Créer un objet de régression linéaire
model = LinearRegression()
# Ajuster la régression avec les entrées et les cibles d'entraînement
mises à l'échelle
model.fit(X_train, Y_train)
# Vérifions les sorties de la régression
# Stocker dans y_hat car c'est le nom 'théorique' des prédictions
Y_hat = reg.predict(Y_train)La façon la plus simple de comparer les cibles et les prédictions est de les tracer sur un nuage de points. Plus les points sont proches de la ligne à 45 degrés, meilleure est la prédiction.
plt.scatter(Y_train, model.predict(X_train))
# Nommons aussi les axes
plt.xlabel('Targets',size=18)
plt.ylabel('Predictions',size=18)
plt.xlim(6,13)
plt.ylim(6,13)plt.show()
# Trouver le R-carré du modèle
r_sq = model.score(X_train, Y_train)
# Afficher le resultat
print("Score ", r_sq)
# Score 0.7968038464188287
# trouvez le R-carré ajusté pour avoir la mesure appropriée
from sklearn.metrics import r2_score
Y_pred = model.predict(X_test)
#
print("R-carre", r2_score(y_true=Y_test, y_pred=Y_pred))
# Resultat
R-carre 0.8019416423856364Conclusion
Dans cet article, nous avons étudié l’un des algorithmes d’apprentissage automatique les plus fondamentaux, à savoir la régression linéaire. Nous avons implémenté la régression linéaire multiple à l’aide de la bibliothèque d’apprentissage automatique Scikit-Learn.
Vous pouvez jouer avec le code et les données de cet article pour voir si vous pouvez améliorer les résultats (essayez de modifier la taille des données d’apprentissage ou de test, les fonctionnalités d’entrée de transformation/mise à l’échelle, etc.). Cependant, il existe d’autres algorithmes voire des mélanges d’algorithme qui peuvent être plus précis que la régression linéaire comme XGBoost ou Random Forest Régression.
Votre commentaire