Un CapsNet (ou réseau neuronal à capsule) est un système de machine learning de la famille des réseaux neuronaux artificiels (RNA) pouvant être utilisé pour mieux modéliser des relations hiérarchiques. Cette approche est une tentative pour reproduire plus fidèlement une organisation neuronale : en utilisant la longueur d’un vecteur d’activité, pour représenter la probabilité que l’entité existe afin de représenter les paramètres.
Un réseau de neurones est un ensemble de neurones formels interconnectés permettant la résolution de problèmes complexes tels que la reconnaissance des formes ou le traitement du langage naturel, grâce à l’ajustement des coefficients de pondération dans une phase d’apprentissage.
Les réseaux de neurones convolutifs (CNN) ont ces dernières années, révolutionné le domaine de l’apprentissage automatique, notamment dans le domaine de la classification d’images. Les différentes applications et avancées dans la compréhension et l’explicabilité de ces modèles nous permettent aussi d’en comprendre ses défauts: problèmes de spatialité ou attaques dites « adversariales » (contradictoires).
C’est quoi un réseau de capsules (CapsNet)
Un CapsNet (ou réseau neuronal à capsule) est un système de machine learning de la famille des réseaux neuronaux artificiels (RNA) pouvant être utilisé pour mieux modéliser des relations hiérarchiques. Cette approche est une tentative pour reproduire plus fidèlement une organisation neuronale : en utilisant la longueur d’un vecteur d’activité, pour représenter la probabilité que l’entité existe afin de représenter les paramètres.
L’idée principale des CapsNet est d’ajouter des structures appelées «capsules» à un réseau de neurones à convolution (CNN) et de réutiliser les sorties de plusieurs de ces capsules pour former des représentations plus stables (par rapport à diverses perturbations) de capsules d’ordre supérieur. La sortie est un vecteur consistant en la probabilité d’une observation et une pose pour cette observation. Ce vecteur est similaire à ce qui est fait par exemple lors de la classification avec une localisation dans CNN.
C’est quoi une capsule
Un CapsNet (ou réseau neuronal à capsule) est un système de machine learning de la famille des réseaux neuronaux artificiels (RNA) pouvant être utilisé pour mieux modéliser des relations hiérarchiques. Cette approche est une tentative pour reproduire plus fidèlement une organisation neuronale : en utilisant la longueur d’un vecteur d’activité, pour représenter la probabilité que l’entité existe afin de représenter les paramètres.
Il existe deux (2) types de capsules
1- Capsule Primaire (PrimaryCaps): Ces capsules procèdent à des opérations de convolutions, afin d’extraire des motifs complexes et leurs attributs à reconnaître dans l’image passée en entrée du réseau.
2- Capsule à chiffre (DigitCaps): Ces capsules procèdent à des opérations semblables à une couche entièrement connectée et produisent en sortie, un nombre de vecteur égal au nombre de classes que le réseau doit reconnaître, étant donné que le vecteur ayant la plus grande norme représente la classification de l’image d’entrée.
Algorithme de routage par accord
L’algorithme de routage par accord constitue l’algorithme de rétropropagation entre les couches de capsules. Il s’agit d’un algorithme itératif qui a pour but de lier les capsules de couches inférieures avec celles de couches supérieures, si l’activation des vecteurs de ces dernières est plus importante lorsqu’elles reçoivent les sorties des premières. L’algorithme a donc des conséquences similaires à un mécanisme d’attention que l’on peut retrouver dans d’autres architectures d’apprentissage profond en permettant aux capsules de couches supérieures ou bien, de s’intéresser à certaines capsules de la couche inférieure ou bien de les ignorer.
Avec le vecteur de sortie, on peut utiliserle puissant mécanisme de routage dynamique, afin d’assurer que la sortie de la capsule est envoyée à un parent approprié pour que les coefficients de sortie totalisent 1 où pour chaque parent possible, la capsule calcule un «vecteur de prédiction» en multipliant sa propre sortie par une matrice de poids. Si ce vecteur de prédiction a un grand produit scalaire avec la sortie d’un parent possible, il y a rétroaction descendante augmentant le coefficient de couplage pour ce parent et diminue pour les autres parents, tout en démontrant que ce mécanisme de routage dynamique est un moyen efficace de mettre en œuvre l’explication qui est nécessaire pour segmenter des objets qui se chevauchent fortement.
Le vecteur ûj|i à partir du vecteur de sortie d’une capsule i de la couche ui précédente est calculée à l’aide d’une matrice de translation et de rotation Wij

Le vecteur de sortie sj d’une capsule j est donc la somme des vecteurs ûj|i avec les i capsules de la couche précédente associée à un coefficient cij :

où les cij sont des coefficients de couplage qui sont déterminés par le processus de routage dynamique itératif.
Dans les couches de capsule convolutives, chaque capsule délivre une grille locale de vecteurs à chaque type de capsule dans la couche ci-dessus, en utilisant différentes matrices de transformation pour chaque membre de la grille ainsi que pour chaque type de capsule.
Procedure d'algorithme de routage par accord
L’architecture moderne d’un réseau neuronal à capsule1 garde son comportement d’auto-encodeur de ses premiers travaux3 . Elle est bien composée de deux parties, une première faisant office d’encodeur et de classifieur et une seconde de décodeur et de reconstruction. Le routage se trouve entre deux (2) couches de capsule consécutive.

Figure 1 : Procédure Algorithme de routage par accord (Source: Capsule Network paper: https://arxiv.org/abs/1710.09829)
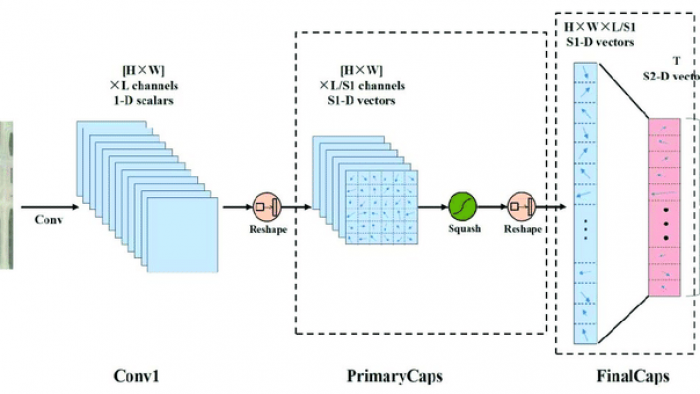
Architecture d’un CapsNet
L’architecture moderne d’un réseau neuronal à capsule1 garde son comportement d’auto-encodeur de ses premiers travaux3 . Elle est bien composée de deux parties, une première faisant office d’encodeur et de classifieur et une seconde de décodeur et de reconstruction. Le routage se trouve entre deux (2) couches de capsule consécutive.

Figure 2 : CapsNet simple à 3 couches (Source: Capsule Network paper: https://arxiv.org/abs/1710.09829)
Exploitation de la Figure 2 : Cette figure représente un CapsNet simple avec 3 couches. Ce modèle donne des résultats comparables aux réseaux convolutifs profonds (tels que profonds (tels que Chang et Chen [2015]). La longueur du vecteur d’activité de chaque capsule dans la couche DigitCaps indique la présence d’une instance de chaque classe et est utilisée pour calculer la perte de classification. Wij est une matrice de poids entre chaque ui , i∈ (1, 32 × 6 × 66) dans PrimaryCapsules et vj , j ∈ (1, 10)
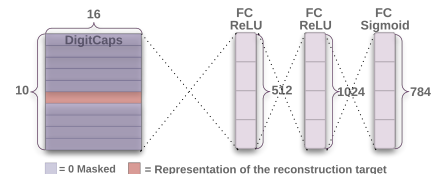
Figure 3 : Architecture du décodeur CapsNet (Source: Capsule Network paper: https://arxiv.org/abs/1710.09829)
Explication de Figure 3 : Structure du décodeur pour reconstruire les données à partir de la représentation de la couche DigitCaps. La distance euclidienne distance euclidienne entre l’image et la sortie de la couche Sigmoïde est minimisée pendant l’apprentissage.
Mise en commun(couche pooling)
Les Capsnets rejettent la stratégie de mise en commun des couches des CNN conventionnels qui réduit la quantité de détails à traiter à la couche supérieure suivante. Le pooling permet un certain degré d’invariance translationnelle (il peut reconnaître le même objet à un endroit quelque peu différent) et permet de représenter un plus grand nombre de types de caractéristiques. Les partisans de Capsnet ne soutiennent que la mise en commun :
– viole la perception biologique des formes dans la mesure où elle n’a pas de cadre de coordonnées intrinsèque ;
– fournit une invariance (en éliminant l’information positionnelle) au lieu d’une équivariance (en démêlant cette information) ;
– ignore le collecteur linéaire qui sous-tend de nombreuses variations entre les images ;
– fait un cheminement statique au lieu de communiquer une « trouvaille » potentielle à la fonction qui peut l’apprécier ;
– endommage les détecteurs de caractéristiques proches, en supprimant les informations sur lesquelles ils s’appuient.
Les CapsNets peuvent répondre au « problème de Picasso » dans la reconnaissance d’image : les images qui ont toutes les parties droites mais qui ne sont pas dans la relation spatiale correcte (par exemple, dans un « visage », les positions de la bouche et de l’œil sont commutées). Pour la reconnaissance d’image, les CapsNets exploitent le fait que, bien que les changements de point de vue aient des effets non linéaires au niveau des pixels, ils ont des effets linéaires au niveau de la pièce de l’objet. Cela peut être comparé à l’inversion du rendu d’un objet à plusieurs parties.
Votre commentaire