De façon simple, un réseau neuronal est un ensemble de neurones qui, généralement, sont regroupés en plusieurs couches (entrée, cachée, sortie). Ces neurones reçoivent des informations en entrée qui sont traitées et transmises à d’autres nœuds jusqu’à générer des sorties sans règles programmées. Car essentiellement, un réseau neuronal résout les problèmes par essais et erreurs.
Le développement de l’Intelligence artificielle, branche de l’informatique fondamentale, a été initié dans le but de simuler les comportements du cerveau humain. Cependant, les premiers travaux visant à modéliser le cerveau étaient antérieurs à l’ère informatique. C’est ainsi qu’en 1943, Mc Culloch (neurophysiologiste) et Walter Pitts (logicien) ont proposé les premières notions de neurone formel dans un article fondateur : “What the frog’s eye tells the frog’s brain.” (Ce que l’œil d’une grenouille dit à son cerveau).
En 1959 Frank Rosenblatt allait mettre en réseau le concept de neurone formel avec une couche d’entrée et une couche de sortie pour simuler le fonctionnement de la rétine et reconnaître des formes. C’est alors, la naissance du perceptron. Mais, cette approche dite connexionniste va vite atteindre ses limites technologiques (en raison de la faible capacité de calcul à l’époque) et théoriques (suite à la publication de l’ouvrage de Marvin Lee Minsky et Seymour Papert en 1969).
Au début des années 80, grâce à l’essor technologique et certaines avancées théoriques comme: “l’estimation du gradient par rétro-propagation de l’erreur” par Hopkins en 1982 et “l’analogie de la phase d’apprentissage avec les modèles markoviens de systèmes de particules de la mécanique statistique (verres de spin)” par John Joseph Hopfield en 1982, l’approche connexionniste allait connaître un développement considérable.
Par contre, au milieu des années 90, avec l’expansion des algorithmes d’apprentissage automatique ou plutôt statistique, l’approche connexionniste allait être remise en veilleuse pour plus tard ré-apparaître comme sujet d’intérêt général sous l’étiquette d’apprentissage profond. Mais alors, c’est sans oublier de signaler deux faits importants:
- l’accès à de grands volumes de données (image surtout) issus d’internet
- et la disponibilité d’une forte puissance de calcul rendant possible l’estimation de millions de paramètres lors de traitement de dizaines, voire, de centaines de couches de neurones aux propriétés complexes et variées.
Réseau de neurones, c’est quoi?
De façon simple, un réseau neuronal est un ensemble de neurones qui, généralement, sont regroupés en plusieurs couches (entrée, cachée, sortie). Ces neurones reçoivent des informations en entrée qui sont traitées et transmises à d’autres nœuds jusqu’à générer des sorties sans règles programmées. Car essentiellement, un réseau neuronal résout les problèmes par essais et erreurs.
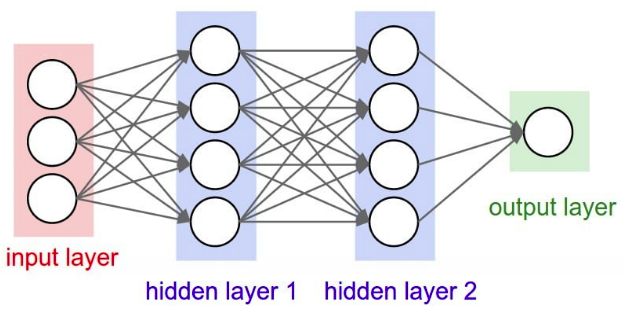
En machine learning, un réseau neuronal est l’association, en un graphe plus ou moins complexe, d’objets élémentaires, les neurones formels. Les principaux réseaux se distinguent par l’organisation du graphe (en couches, complets. . . ), c’est-à-dire leur architecture, son niveau de complexité (le nombre de neurones, présence ou non de boucles de rétroaction dans le réseau), par le type des neurones (leurs fonctions de transition ou d’activation) et enfin par l’objectif visé : apprentissage supervisé ou non, optimisation, systèmes dynamiques.
Les réseaux de neurones, pourquoi?
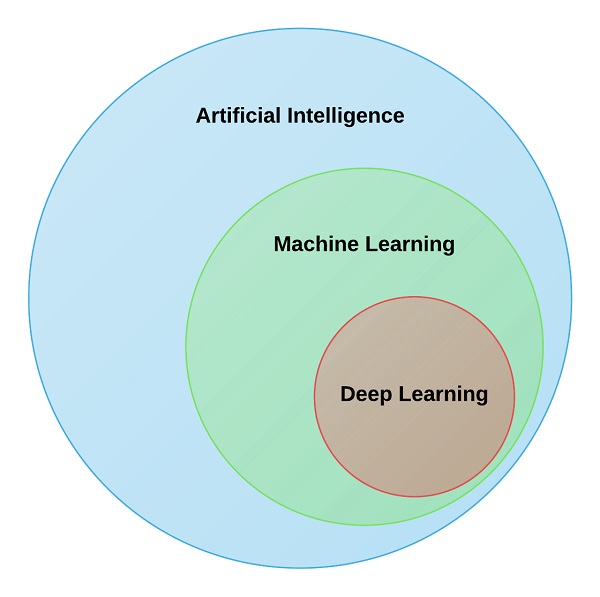
Pour mieux comprendre le pourquoi des réseaux de neurones artificiels, il me semble tout à fait normal de vous faire une brève initiation à l’apprentissage profond. Il est vrai que nous n’allons pas nous éterniser là-dessus. Néanmoins, un petit passage sur quelques points précis va vous permettre d’avoir une meilleure idée sur les réseaux de neurones artificiels.
C’est clair que l’apprentissage profond est un sous-élément de l’intelligence artificielle, il s’inspire de la façon dont les humains acquièrent certains types de connaissances. Dans sa forme la plus simple, le Deep Learning (les réseaux de neurones artificiels) peut être considéré comme un moyen d’automatiser l’analyse prédictive. Alors que les algorithmes traditionnels d’apprentissage automatique sont linéaires, les algorithmes de Deep Learning sont empilés dans une hiérarchie de complexité et d’abstraction croissantes.
Fonctionnement et utilisation des réseaux de neurones
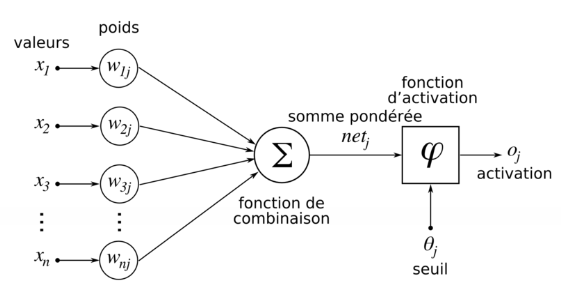
En apprentissage automatique, pour revenir dans les détails de fonctionnement d’un neurone, ce dernier fait une combinaison linéaire des entrées qu’il reçoit, à laquelle il ajoute une valeur appelée biais. Une fonction non linéaire, dite d’activation, (comme par exemple tangente hyperbolique) est alors appliquée à la valeur de sortie. Cette valeur est ensuite transmise à la couche de neurone suivante. Chaque neurone effectue ainsi un calcul très rudimentaire, et c’est la succession des couches de neurones qui permet d’obtenir des réseaux complexes.
Durant cette phase dite « d’entraînement », le réseau va ajuster automatiquement les paramètres de chaque neurone, c’est-à-dire les valeurs des poids et du biais afin de minimiser l’erreur moyenne calculée sur l’ensemble des exemples entre la sortie attendue et celle observée. L‘hypothèse est qu’après cette phase d’entraînement, le réseau sera capable de traiter de manière satisfaisante de nouveaux exemples, dont la sortie est inconnue, en fonction de ce qu’il a « appris ». Cette phase d’apprentissage peut se faire sur des caractères manuscrits, des objets dans une image, des sons, etc. (source)
Un réseau neuronal a trois fonctions :
- Saisie de la notation
- Calcul de la perte
- Mise à jour du modèle, qui relance le processus
Grâce à leur capacité de classification et de généralisation, les réseaux de neurones sont généralement utilisés dans des problèmes de nature statistique, tels que la classification automatique de codes postaux ou la prise de décision concernant un achat boursier en fonction de l’évolution des cours. Autre exemple, une banque peut créer un jeu de données sur les clients qui ont effectué un emprunt constitué de leur revenu, de leur âge, du nombre d’enfants à charge… et s’il s’agit d’un bon client. Si ce jeu de données est suffisamment grand, il peut être utilisé pour l’entraînement d’un réseau de neurones. La banque pourra alors présenter les caractéristiques d’un potentiel nouveau client, et le réseau répondra s’il sera bon client ou non, en généralisant à partir des cas qu’il connaît.
Les deux types de réseau de neurones les plus connus
- Les réseaux de neurones feed-forward
En effet, feed-forward (propagation avant) signifie tout simplement que la donnée traverse le réseau d’entrée à la sortie sans retour en arrière de l’information. Typiquement, dans la famille des réseaux à propagation avant, on distingue les réseaux monocouches (perceptron simple) et les réseaux multicouches (perceptron multicouche).
Le perceptron simple est dit simple parce qu’il ne dispose que de deux couches ; la couche en entrée et la couche en sortie. Le réseau est déclenché par la réception d’une information en entrée. Le traitement de la donnée dans ce réseau se fait entre la couche d’entrée et la couche de sortie qui sont toutes reliées entre elles. Le réseau intégral ne dispose ainsi que d’une matrice de poids. Le fait de disposer d’une seule matrice de poids limite le perceptron simple à un classificateur linéaire permettant de diviser l’ensemble d’informations obtenues en deux catégories distinctes. (Source)
Le Perceptron simple est caractérisé par:
- Le perceptron est constitué d’un unique neurone
- La fonction de transfert est une fonction de seuil ou toutes autres fonctions du même type.
- A la différence avec le modèle de neurone formel est que le neurone peut « apprendre » en utilisant les règles de Hebb/RosenBlatt.
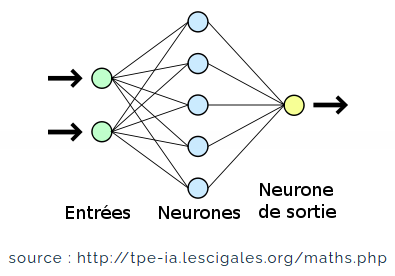
À la différence du perceptron simple, le perceptron multicouche dispose entre la couche en entrée et la couche en sortie une ou plusieurs couches dites « cachées ». Le nombre de couches correspond aux nombres de matrices de poids dont disposent le réseau. Un perceptron multicouche est donc mieux adapté pour traiter les types de fonctions non linéaires.
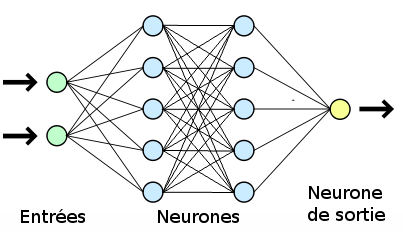
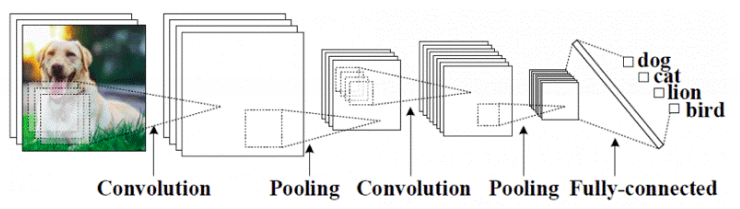
Dans le cas de traitement d’informations plus complexes et très variés, la création de réseaux de neurones spécialisés doit-être envisagée. Les réseaux de neurones qui répondent à cette description sont connus sous le nom de réseau de neurones à convolution (de l’anglais CNN qui signifie: Convolutional Neural Network). Ces réseaux peuvent être imaginés comme une compilation d’un segment d’informations pour au final traiter l’ensemble de l’information (par exemple le traitement d’image, de vidéos, de textes).
2. Les réseaux de neurones récurrents
Les réseaux récurrents (ou RNN pour Recurrent Neural Networks) sont des réseaux de neurones dans lesquels l’information peut se propager dans les deux sens, y compris des couches profondes aux premières couches. En cela, ils sont plus proches du vrai fonctionnement du système nerveux, qui n’est pas à sens unique.
Ces réseaux possèdent des connexions récurrentes au sens où elles conservent des informations en mémoire : ils peuvent prendre en compte à un instant t un certain nombre d’états passés. Pour cette raison, les RNNs sont particulièrement adaptés aux applications faisant intervenir le contexte, et plus particulièrement au traitement des séquences temporelles comme l’apprentissage et la génération de signaux, c’est-à-dire quand les données forment une suite et ne sont pas indépendantes les unes des autres. Néanmoins, pour les applications faisant intervenir de longs écarts temporels (typiquement la classification de séquences vidéo), cette « mémoire à court-terme » n’est pas suffisante.
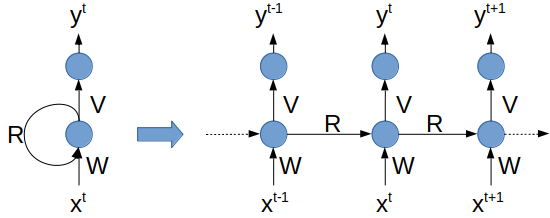
En effet, les RNNs « classiques » (réseaux de neurones récurrents simples ou Vanilla RNNs) ne sont capables de mémoriser que le passé dit proche, et commencent à « oublier » au bout d’une cinquantaine d’itérations environ. Ce transfert d’information à double sens rend leur entraînement beaucoup plus compliqué, et ce n’est que récemment que des méthodes efficaces ont été mises au point comme les LSTM (Long Short Term Memory).
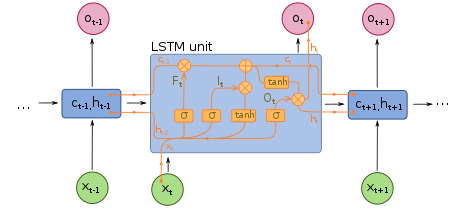
Ces réseaux à « large mémoire à court-terme » ont notamment révolutionné la reconnaissance de la voix par les machines (Speech Recognition) ou la compréhension et la génération de texte (Natural Language Processing). D’un point de vue théorique, les RNNs ont un potentiel bien plus grand que les réseaux de neurones classiques : des recherches ont montré qu’ils sont « Turing-complet » (ou Turing-complete), c’est à dire qu’ils permettent théoriquement* de simuler n’importe quel algorithme. Cela ne donne néanmoins aucune piste pour savoir comment les construire pour cela dans la pratique.
Bonus!
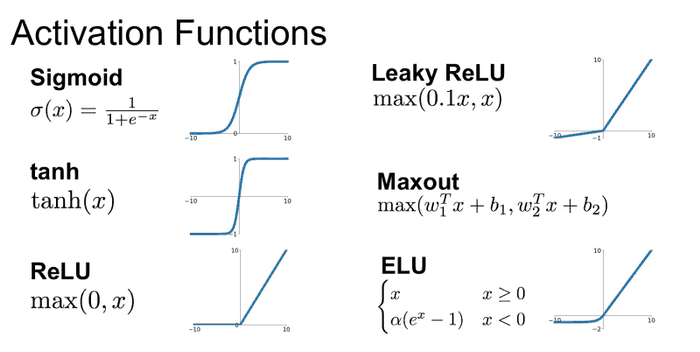
Et pour finir, je ne vais pas introduire un nouveau sujet, loin de là, rassurez-vous. Cependant, je vous présente juste en bonus: les fonctions d’activation. Eh oui je sais, c’est tout un autre article à consacrer à ce sujet. Mais bon, ci-dessous c’est le bonus, au prochain, on y reviendra sur les détails.
Votre commentaire